




.jpg?width=300&name=Frame%204728%20(1).jpg)

Wejdź głębiej w działanie klasycznych testów A/B, poznaj prawdziwe znaczenie istotności statycznej i odkryj pułapki, które zagrażają wynikom Twoich testów.
Testy A/B są jedną z najszerszych technik, służących optymalizacji stron internetowych. Pozwalają podejmować mądrzejsze oraz oparte na danych decyzje. Proponowane zmiany nie są oceniane jedynie na podstawie intuicji (albo przez kogoś, kto posiada od Ciebie bardziej zaawansowane zdolności argumentowania), ale raczej bazują na pożądanych, od razu widocznych, celach (jak np. CTR), czy tych długoterminowych (takich, jak stanie się płacącym konsumentem). Jednocześnie test pozwala ochronić Cię przed popełnieniem poważnego błędu, który mógłby drastycznie zaszkodzić zaangażowaniu użytkowników. Przyjrzyjmy się bliżej klasycznym testom A/B, zapoznajmy się ze znaczeniem istotności statystycznej i odkryjmy pułapki, które czyhają na drodze do wyników. Końcowym elementem będzie przedstawienie kilku alternatyw do optymalizacji klasycznych testów A/B.
Intuicyjnie procedura jest prosta: najpierw tworzysz inną opcję Twojej oryginalnej strony. Następnie rozdzielasz losowo ruch na stronie między dwie testowane wersje (przydzielając przypadkowo odwiedzających według jakiegoś prawdopodobieństwa). Ostatnim etapem jest zebranie danych, wybranie lepiej performującej opcji i usunięcie tej, która wypadła zdecydowanie gorzej. Brzmi banalnie? Jednak wcale takie nie jest.
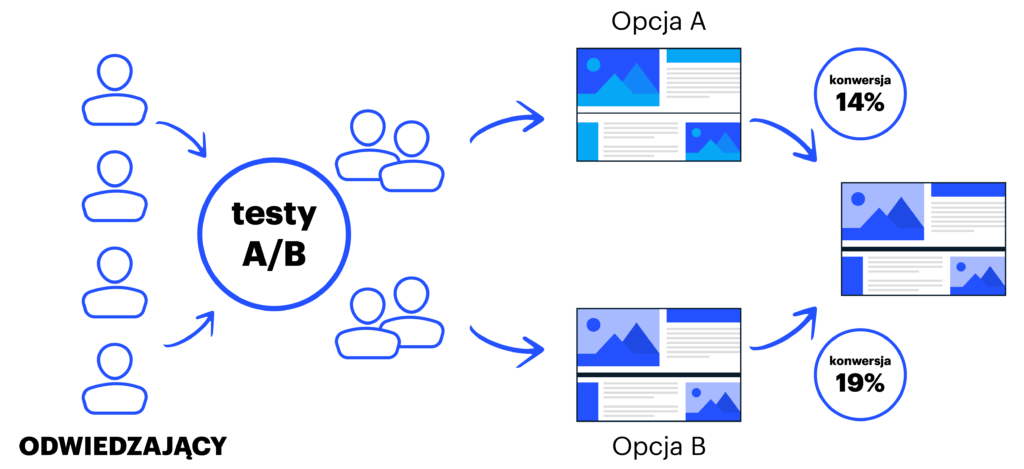
Jak rozpocząć proces testowania hipotez?
Najpierw należy zrozumieć, w którym miejscu możliwe jest popełnienie błędu. Są na to dwa sposoby: po pierwsze, istnieje możliwość błędnego odrzucenia hipotezy zerowej. Po krótkim zapoznaniu się z danymi można stwierdzić, że istnieje różnica w działaniu nowej i pierwotnej wersji strony. Jednak w rzeczywistości taka różnica nie ma miejsca, a zaobserwowana zmiana jest przypadkowa. Taki rodzaj błędu nazywany jest błędem typu I lub fałszywym pozytywem.
Drugą z możliwych pułapek jest zbyt pobieżne zapoznanie się z działaniem każdej z wersji (nowej i dotychczasowej), przez co nie istnieje prawdopodobieństwo niezauważenia większej różnicy między nimi i wyciągnięcia błędnych wniosków, że różnica nie istnieje. Taki rodzaj błędu nazywany jest błędem typu II lub fałszywym negatywem.
Jak można uniknąć błędów?
Najprościej mówiąc: ustal odpowiednią wielkość próby. Aby ją określić, musisz wstępnie zdefiniować kilka parametrów testu:
- aby uniknąć fałszywie pozytywnych błędów, należy ustalić poziom pewności, nazywany również istotnością statystyczną. Powinna być to niewielka liczba dodatnia, często określana wartością 0,05, co oznacza, że istnieje 5% ryzyko na popełnienie błędu typu I. Prościej mówiąc, istnieje 5% szans na zauważenie różnicy w funkcjonowaniu dwóch wariantów, gdy w rzeczywistości ta różnica nie istnieje (5% szansa na popełnienie błędu). Ta wspólna stała określana jest jako posiadanie „95% pewności”.
- wiele osób przeprowadzających testy poprzestałoby na pierwszym parametrze, aby uniknąć fałszywie negatywnych błędów. Warto jednak zdefiniować jeszcze dwa dodatkowe właściwości: minimalną różnicę w funkcjonowaniu (o ile istnieje), którą chcesz wykryć oraz prawdopodobieństwo zaobserwowania różnicy, jeśli taka ma miejsce. Drugi z parametrów nazywany jest mocą statystyczną i często określany jest na domyślnym poziomie o wartości 80%.
Obliczanie wielkości próby może wydawać się wyczerpujące, a jej wynik często daje wrażenie zbyt dużego, standardowe podejście wymaga uważnego śledzenia tego procesu, w przeciwnym razie może się okazać, że jesteś skazany na porażkę. W rzeczywistości nawet jeśli stosujesz się do powyższych zasad, zawsze istnieje ryzyko zaobserwowania nieprawidłowego wyniku. Warto zastanowić się, dlaczego.
Czy można całkowicie zaufać wynikom testów?
Mimo że testowanie hipotez wygląda obiecująco, w rzeczywistości często jest dalekie od ideału. Opiera się na pewnych ukrytych założeniach, które w praktyce często nie są satysfakcjonujące. Pierwsze z nich zazwyczaj jest dość pewne – przypuszczasz, że próby (czyli odwiedzający, widzący testowany wariant) są od siebie niezależne, a ich zachowanie i ostateczny wynik bezpośrednio na siebie nie wpływają. To założenie jest zazwyczaj słuszne, chyba że wielokrotnie pokazujesz tym samym odbiorcom różne zdarzenia. Drugim założeniem jest to, że próbki mają identyczną wielkość. W uproszczeniu oznacza to, że prawdopodobieństwo konwersji jest takie samo dla wszystkich odwiedzających Twoją witrynę. To oczywiście nie jest prawdą. Wskaźnik konwersji może zależeć od czasu, lokalizacji, preferencji użytkownika, osoby polecającej produkt lub kategorię i wielu innych czynników. Przykładowo, jeśli w trakcie testów prowadzona jest kampania marketingowa, może ona spowodować zwiększenie ruchu np. z Facebooka. To z kolei może mieć wpływ na drastyczną i nagłą zmianę CTR, bazującą na tym, że leady pochodzące z tej konkretnej kampanii odznaczają się innymi cechami, niż ma to miejsce w przypadku całej grupy użytkowników odwiedzających witrynę. W konsekwencji niektóre z bardziej zaawansowanych technik optymalizacyjnych uzależnione są od tych różnic. Ostatnim założeniem jest to, że miary, które bierzesz za wzorzec, np. CTR czy współczynnik konwersji, posiadają rozkład normalny (rozkład Gaussa). Może to zabrzmieć, jak niejasny termin matematyczny, jednak wszelkiego rodzaju wzorce na poziom ufności zależą właśnie od tego założenia – im jest ono bardziej zróżnicowane, tym jednocześnie jest bardziej realne. Uogólniając, im większa próba i wyższy poziom konwersji, tym hipoteza jest mocniejsza (mówi o tym matematyczna teoria, nazywana centralnym twierdzeniem granicznym).
Na jakie pułapki należy uważać i na jakich założeniach się opierać przeprowadzając testy A/B?
Istnieją dwa rodzaje zagrożeń. Po pierwsze, platformy do testów A/B często oferują wyświetlanie dotychczas zebranych wyników w czasie rzeczywistym. To z jednej strony daje Ci przejrzystość i poczucie kontroli. Z drugiej zaś może skutkować nadmiernymi reakcjami, czy nawet paniką, względem wyników, które nie są jeszcze kompletne. Przerwanie testu przed osiągnięciem wcześniej określonej próby przy jednoczesnym ciągłym analizowaniu bieżących wyników oraz zatrzymanie się w pierwszym momencie, w którym został osiągnięty próg istotności statycznej, to gwarancja popełnienia błędu w trakcie badań. To powoduje nie tylko tendencyjność statyczną w kierunku poszukiwania różnicy (która nie istnieje), ale dodatkowo ta tendencja nie jest możliwa do skorygowania (na przykład poprzez żądanie wyższego poziomu istotności). Drugą pułapką jest generowanie zbyt wysokich oczekiwań względem wydajności zwycięskiego wariantu z przeprowadzanego testu. W związku ze statystycznym efektem, zwanym regresją w kierunku średniej, wydajność lepiej performującej opcji może nie być aż tak wartościowa, jak to miało miejsce podczas testu. Mówiąc wprost – zwycięski wariant mógł uzyskać ten tytuł nie tylko dlatego, że naprawdę był znacznie lepszy od drugiego, ale również z tego względu, że po prostu miał więcej ‘szczęścia’. Jego dobra passa kończy się, a wydajność zaczyna się zmniejszać.
Czy mamy alternatywę dla testów A/B?
Oczywiście, że tak! Świat optymalizacji stron internetowych posiada bardzo szeroką ofertę use-case’ów, gdzie tylko dla niektórych z nich pasują testy A/B. Załóżmy, że przeprowadzasz test na stronie, która od dawna dobrze funkcjonuje, natomiast zmiana, jaką chcesz przeprowadzić, ma być trwała i możliwa do realizacji dla wszystkich użytkowników także w dłuższej perspektywie czasu po zakończeniu testu. W takiej sytuacji istotne jest, aby wykonać dokładne porównanie działania dwóch wariacji, co często jest zwyczajnie niemożliwe.
Na przykład, jeśli chcesz przetestować, który z tytułów najlepiej performuje dla danego artykułu i wiesz, że będzie on wyświetlany na Twojej stronie głównej tylko przez kilka godzin. Oznacza to, że musisz szybko zauważyć, który z nich ma wyższy wskaźnik otwieralności, a następnie jak najszybciej wykorzystać tę wiedzę. W tym przypadku możesz zastosować metodę multi-armed bandit (metodę wieloramiennego bandyty), która Ci w tym pomoże. Polega ona na tym, że dzieli ruch między zastosowane warianty w zależności od zaobserwowanej dotychczas wydajności i poziomu pewności. To przybliża Cię do uznania, która z opcji jest ‘naprawdę’ najlepsza dla szybszej konwergencji. To również pierwszy poziom optymalizacji.
Pogłębieniem optymalizacji jest dążenie do prawdziwej personalizacji, gdzie zarówno ręcznie, jak i automatycznie możesz dopasować użytkowników do różnych wariantów. Jako przykład ręcznej kontroli możesz ustawić, aby użytkownicy odwiedzający Holandię w Dniu Królowej widzieli pomarańczowe tło na stronie głównej.
Takie ręczne sterowanie ma sens w wielu sytuacjach, jednak nie funkcjonuje zbyt poprawnie: powiedzmy, że masz specjalną promocję dla przekierowanych z Facebooka osób odwiedzających Twoją witrynę. Co powinieneś im pokazać? Gdy zaczniesz wymyślać nowe warianty i segmenty użytkowników, reguły szybko zaczną się komplikować – i jest tu element domysłu: myślisz, że powinieneś trafić w dziesiątkę, ale nikt tak naprawdę nie wie, jak ona wygląda. Dlatego właśnie innym podejściem, jakie w niektórych przypadkach może działać lepiej, jest podejście automatycznej personalizacji (m.in. marketing automation). Załóżmy, że prowadzisz stronę z przepisami. Masz zaplanowane miejsce, w którym chcesz użytkownikowi pokazać polecany przez Ciebie przepis na podstawie jego wcześniejszych wizyt na stronach kulinarnych. W tym przypadku automatyczna personalizacja sprawdzi się doskonale.

Przeczytaj również nasz artykuł na temat personalizacji – https://www.persooa.com/blog/jak-zaprojektowac-personalizacje-ktora-przyniesie-wymierne-efekty/
Podsumowując
Testy A/B mogą być niezwykle skuteczne, ale zarazem bardzo mylące, jeśli nie zostaną przeprowadzone w odpowiedni sposób. Osiągniecie punktu istotności statystycznej, jest kluczowe do uzyskania wiarygodnych wyników. Aby móc się znaleźć w tym miejscu, musisz ustalić wymagane parametry oraz oszacować, a następnie trzymać się ustalonej wielkości próby. Częste sprawdzanie wyników testu jest klasycznym błędem, który może skutkować utratą docelowego wyniku testu. Jeśli potrzebujesz krótkofalowej optymalizacji, powinieneś zastanowić się nad takimi metodami, jak wspomniany wcześniej multi-armed bandit (wieloramienny bandyta) lub inteligenta personalizacja, oparta na uczeniu maszynowym.
